研究设计
研究结果
模型版本对诊断准确性的影响
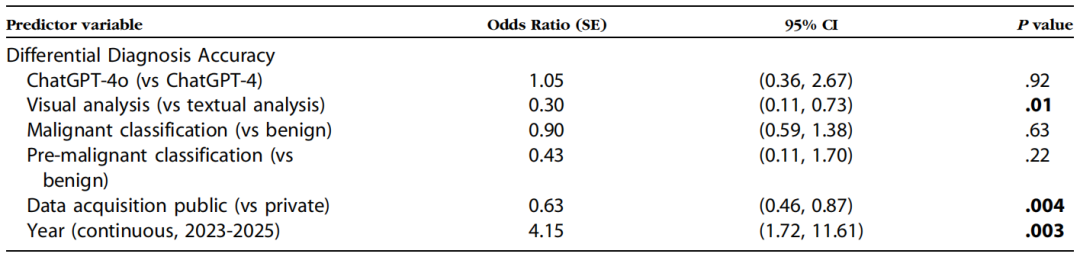
研究显示,ChatGPT-4o在诊断准确性上显著优于ChatGPT-4。在首位诊断准确率方面,ChatGPT-4o为68.12%,而ChatGPT-4仅为38.26%;在鉴别诊断准确率方面,分别为75.83%和60.47%(P = 0.0038)。这一差异归因于ChatGPT-4o在2024年发布时增强了多模态推理能力。
提示类型对诊断准确性的影响
视觉提示的整体诊断准确率高于文本提示(69.60% vs 65.00%),表明图像信息为模型提供了更多诊断线索。然而,Logistic回归分析显示,与文本提示相比,视觉提示的准确率反而显著降低(OR = 0.30,P = 0.01),提示视觉输入可能存在信息处理偏差(表1)。
表1:ChatGPT 在关键变量上的逻辑回归结果
病变类型与肤色差异
恶性病变(如
数据来源与时间趋势
使用公共数据集的诊断准确率低于私有数据集(67.51% vs 70.10%,P = 0.0295)。Logistic回归进一步证实,公共数据集的使用显著降低诊断准确性(OR = 0.63,P = 0.004)。此外,研究年份与诊断准确性呈正相关(OR = 4.15,P = 0.003),表明模型性能在逐年提升(表1)。
偏倚与异质性评估
漏斗图显示研究分布无明显不对称性(Egger检验P = .191),提示不存在显著发表偏倚。然而,研究间存在高度异质性(I² = 92.9%),可能与数据集差异、提示工程方法、病变类型等因素有关(图1)。
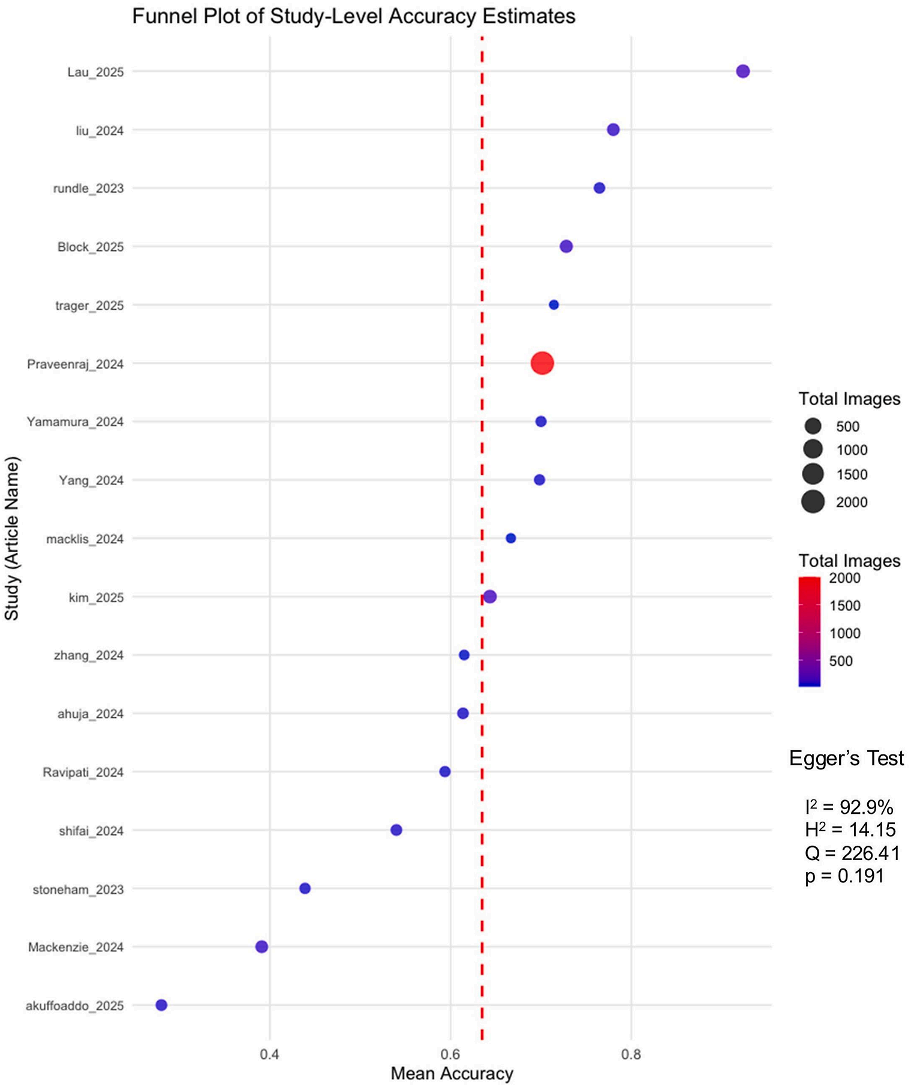
图1:研究层面准确性估计和偏倚评估的漏斗图
参考文献:Chen R, Nguyen DH, Fettel KD, et al. Diagnostic accuracy of ChatGPT in dermatology: A meta-analysis of textual versus visual prompts. J Am Acad Dermatol. 2026;94(1):288-289. doi:10.1016/j.jaad.2025.09.016
医脉通是专业的在线医生平台,“感知世界医学
 我要投稿
我要投稿














{kind=link}